Make transcription resilient to network interruptions
Handling unstable networks is made simpler thanks to the stateless nature of the transcription websocket.
In fact, in a real-time streaming configuration, as soon as you send audio you get instantaneous transcription back. This means that if at any moment you lose your connection with Nabla servers, you can resume later with practically no loss as long as you have a buffer between the audio source (e.g., microphone) and the distant transcription server (Nabla).
Maintaining a buffer of audio chunks
Since audio will continue to flow from its source regardless of network interruptions, you need to locally buffer the audio you are streaming to the Nabla transcription websocket.
In an ideal situation, the buffer will remain practically empty as it’s filled from the audio source (e.g., microphone) at a rate of 1× real time, and emptied at the same rate.
Once the internet connection is lost, the buffer will keep filling but will not be emptied since the emptying happens when you send audio to Nabla servers. You need to make sure the buffer’s size is big enough to accommodate the full encounter’s audio even though the network loss phases should remain pretty short.
Then, when the internet is back, you can resume emptying the buffer but this time at the fastest possible rate allowed by Nabla servers:
- You can either leverage the experimental audio chunk acknowledgment feature protocol (requires opt-in) so that the streaming speed is capped by the speed of acknowledgment from Nabla servers;
- Otherwise, you can hardcode a maximum speed of 2× real time.
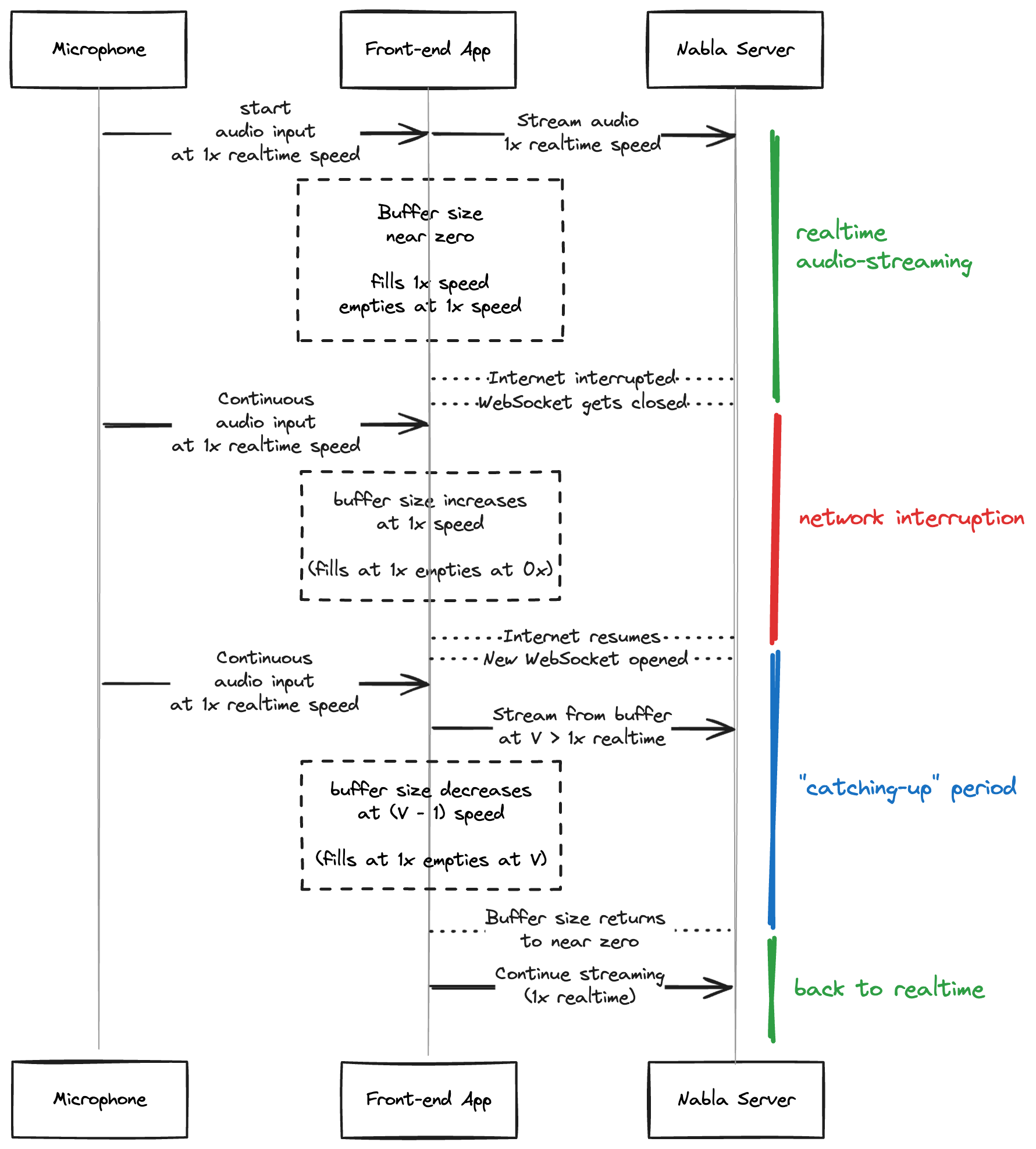
Example sequence diagram of audio buffer before, during and after a network interruption.
Leveraging audio chunk acknowledgement to empty the buffer
This guide uses an experimental audio chunk acknowledgment feature that requires opt-in. If interested, please contact us.
Once this experimental feature is enabled for your organization, you can start sending enable_audio_chunk_ack: true in the configuration (first frame) of the transcription websocket.
{
"object": "listen_config",
"output_objects": ["transcript_item"],
"encoding": "pcm_s16le",
"sample_rate": 16000,
"language": "en-US",
"streams": [{ "id": "single_stream", "speaker_type": "unspecified" }],
"enable_audio_chunk_ack": true
}
Enabling this new protocol has the following implications:
-
Enforced sequentiality
Each audio chunk is required to have a
seq_id. Within the same stream, sequential ids should be sequential: increases by 1 from one audio chunk to the next oneseq_id(chunk(n+1)) = seq_id(chunk(n)) + 1. This is a strict requirement (the websocket will close with an error if it is not met) because out-of-order audio chunks will yield bad or irrelevant transcription. The initial value per stream per websocket for the first chunk can be any arbitrary integer value, but we recommend you start at zero for each new encounter and keep it sequential cross-websockets for easier debugging of buffer consistency. -
Continuous acknowledgement
Nabla server will continuously send acknowledgement frames that look like the following
{
"object": "audio_chunk_ack",
"stream_id": "single_stream",
"ack_id": 42
}A single acknowledgement frame should be considered as an acknowledgement for all audio chunks with a
seq_idprior to or equal to the mentionedack_id. In fact, depending on the frequency and backpressure handling, Nabla server might batch acknowledgement of multiple chunks in one frame: acknowledgement is not one-to-one. -
Cooperative handling of backpressure
Clients should not stream faster than server is sending acknowledgements. Exceeding the limit of 10 seconds of in-flight audio, i.e. audio chunks sent but not yet acknowledged, will result in a buffer overflow error from Nabla servers. Server's acknowledgement speed is tied to the transcription speed, you can assume that audio that has been acknowledged has also been transcribed. Thus, as long as an acknowledgement is received you can clear the related audio chunks from your buffer.
Basically, your audio buffer will be a first-in-first-out queue where audio chunks pass through two states: queued then sent. Chunks in the state sent are those not supposed to grow larger than 10 seconds: This means clients should refrain from sending (moving chunks from queued to sent) until acknowledgement is received and results in deleting items from sent.
Handling edge-cases
User ends encounter during catch-up period
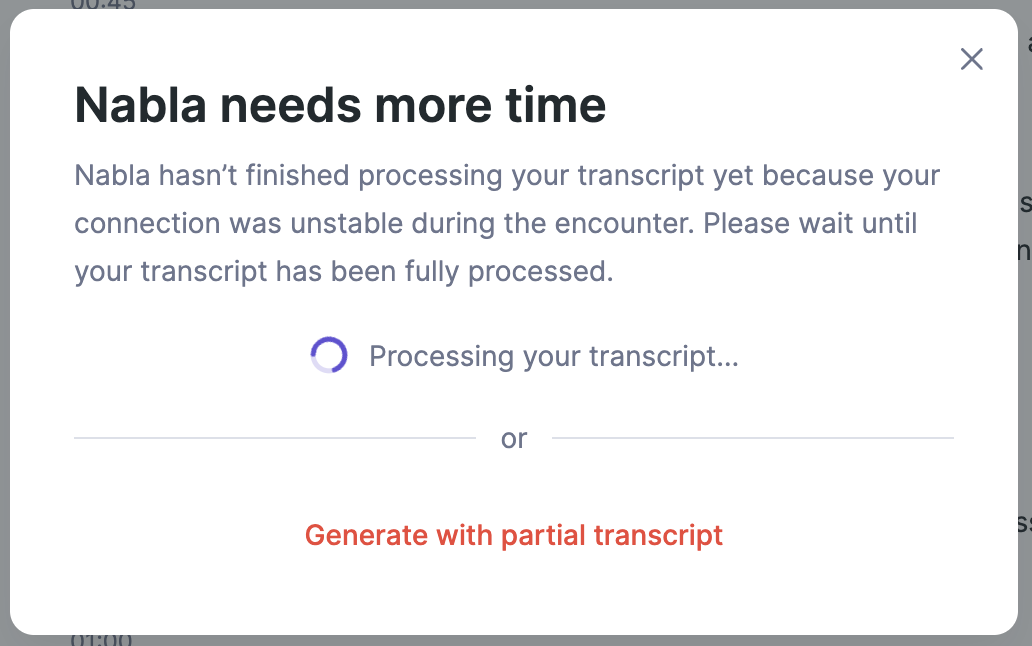
Example prompt for when ending an encounter while still catching-up
Given that users can end their encounter at any moment, you might in some case need a special handling. For instance, if they end the encounter right after an interruption then the buffer is still not emptied yet (still in the catching-up period) so the transcription is still not fully done.
In this case, we recommend you stop capturing audio (to stop filling the buffer) and prompt the user with the extra-waiting time there will be to catch-up, while keeping it possible to skip and generate the note right away.
Also, don't forcefully close the websocket once all audio has been streamed and acknowledged, but send the end frame { "object": "end" } and wait for server to post-process, send final transcript items then close the websocket itself.
Don't hesitate to contact our support team if you have any questions or feedback.